什么是内存模型
Go的内存模型特指在并发的场景下,一个goroutine所写的变量在另一个goroutine能在哪些情况下被观察到
在计算中,内存模型描述了多线程如何通过内存的交互来共享数据
官方建议
程序可能会并发地访问/修改一些变量,多个goroutine的并发访问一定要保证“可串行化”,尤其是绝对不允许出现数据竞争的场景下 为了保证数据访问的串行化访问,没有数据竞争,在Go语言中,尽量通过channel或者各种同步原语对数据的并发访问进行保护,例如sync 、sync/atomic等 强烈推荐阅读官方文档
If you must read the rest of this document to understand the behavior of your program, you are being too clever. Don’t be clever.
C语言中的内存可见性
内存可见性是一个通用性质的问题,类似于 c/c++,golang,java 都存在相应的策略。作为比较,我们先思考下 c 语言,在 c 里面却几乎没有 happens-before 的理论规则,究其原因还是由于 c 太底层了,常见 c 的内存可见性一般用两个比较原始的手段来保证:
volatile关键字(很多语言都有这个关键字,但是含义大相径庭,这里只讨论 c )- memory barrier
volatile
volatile 声明的变量不会被编译器优化掉,在访问的时候能确保从内存获取,否则很有可能变量的读写都暂时只在寄存器。但是,c 里面的 volatile 关键字并不能确保严格的 happens-before 关系,也不能阻止 cpu 指令的乱序执行,且 volatile 也不能保证原子操作。
以一个常见的c代码为例:
// done 为全局变量
int done = 0;
while ( ! done ) {
/* 循环内容 */
}
// done 的值,会在另一个线程里会修改成 1;
这段代码,编译器根据自己的优化理解,可能在编译期间直接展开翻译成(或者每次都直接取寄存器里的值,寄存器里永远存的是 0 ):
while ( 1 ) {
/* 循环内容 */
}
memory barrier
内存屏障(memory barrier),又叫做内存栅栏(memory fence),分为两类:
- 编译器屏障(又叫做优化屏障)—— 针对编译期间的代码生成
- cpu 内存屏障 —— 针对运行期间的指令运行
这两类屏障都可以在 c 里面可以手动插入,比如以下:
// 编译器屏障,只针对编译器生效(GCC 编译器的话,可以使用 __sync_synchronize)
#define barrier() __asm__ __volatile__("":::"memory")
// cpu 内存屏障
#define lfence() __asm__ __volatile__("lfence": : :"memory")
#define sfence() __asm__ __volatile__("sfence": : :"memory")
#define mfence() __asm__ __volatile__("mfence": : :"memory")
优化屏障能阻止乱序代码生成和 cpu 内存屏障能阻止乱序指令执行。有很多人会奇怪了,我写 c 代码的时候,好像从来没有手动插入过内存屏障?其实 c 库的锁操作(比如 pthread_mutx_t )是天然自带屏障的。
小结:c 语言保证内存可见性的的方式非常简单和原始,几乎是在指令级别的操作考虑。
Happens Before
以下若无特别说明,线程和goroutine可认为是同一概念,不严格区分
在单线程中,对一个变量的读写“看上去”和我们编码的顺序是一致的。为什么说是“看上去”(as if)呢?因为不论是编译器还是处理器,出于执行效率等有方面考虑,都有可能对实际的指令进行重排,前提是在单线程下重排不会改变原始编程语句定义的行为。但这种保证只在同一线程生效,换句话说,语句的执行顺序和结果在可见性上对其他的在的goroutine上可能是不一样的。举个例子,如果一个goroutine执行了a=1; b=2; 另外的一个goroutine可能会在看到a=1之前先看到b=2 。这种可见性在并发情况下通常是不可预测的。
为了描述这种并发读写,Go官方定义了一个概念,叫做happens before,这个概念简单来说就是指定了一种偏序关系,用于描述Go程序中内存操作的“顺序”。偏序关系的重要性质是具有传递性,这构成了串行化的基础。
e1 happens before e2 -> e2 happens after e1
e1 does not happens before e2 && e1 does not happen after e2, e1 and e2 happen CONCURRENTLY
在单线程的情况下,这个happens-before的顺序就是程序本身指定的顺序。
要注意这个其实不是物理时间上的先后,更多地是描述了一种“可见性”,先发生的事件结果是一定能被后发生的事件观测到的。
比较正式地:
假设有个变量v,如果满足以下条件,则对这个变量的读 (r)可以观测到对v的写(w)
1. r does not happens before w
2. There is no other write w' to v that happens after w but before r.
更一般的,为了保证r能读到对v的特定w,需要保证w是r可观测到的唯一一次写,即只要下述条件被满足,才能满足r能够观察到w
1. w happens before r.
2. Any other write to the shared variable v either happens before w or after r.
后面这个条件比前面的条件更强,它要求与w/r没有并发发生的写操作
单线程的情况下,由于没有并发,上面两个条件其实是等价的:一个r能观测到最近的一次w对v的写入。但在并发场景下,有多个线程同时访问一个变量时,不同线程之间必须通过一些同步机制去建立一系列happens-before条件,以保证r能看到它真正想要的那次w
对v的零值初始化可视为一次w
对超过一个machine word的变量读写,可视为多个 machine-word-sized的乱序操作
同步(Synchronization)
初始化
If a package p imports package q, the completion of q’s init functions happens before the start of any of p’s.
import package 的时候,如果 package p 里面执行 import q,那么逻辑顺序上 package q 的 init 函数执行先于 package p 后面执行任何其他代码。
// package p
import "q" // 1
import "x" // 2
执行(2)的时候,package q 的 init 函数执行结果对(2)可见,换句话说,q 的 init 函数先执行,import "x" 后执行。
创建goroutine
The go statement that starts a new goroutine happens before the goroutine’s execution begins.
该规则说的是 goroutine 创建的场景,创建函数本身先于 goroutine 内的第一行代码执行。
var a int
func main() {
a = 1 // 1
go func() { // 2
println(a) // 3
}()
}
按照这条 happens-before 规则:
- (2)的结果可见于(3),也就是 2 <= 3;
- (1)天然先于(2),有 1 <= 2
happens-before 属于一种偏序规则,具有传递性,所以 1<=2<=3,所以 golang 程序能保证在 println(a) 的时候,一定是执行了 a=1 的指令的。再换句话说,主 goroutine 修改了 a 的值,这个结果在 协程里 println 的时候是可见的。
销毁goroutine
The exit of a goroutine is not guaranteed to happen before any event in the program.
该规则说的是 goroutine 销毁的场景,这条规则说的是,goroutine 的 exit 事件并不保证先于所有的程序内的其他事件,或者说某个 goroutine exit 的结果并不保证对其他人可见。
var a string
func hello() {
go func() { a = "hello" }()
print(a)
}
换句话说,协程的销毁流程本身没有做任何 happens-before 承诺。上面的实例里面的 goroutine 的退出结果不可见于下面的任何一行代码。
使用Channel
A send on a channel happens before the corresponding receive from that channel completes.
The closing of a channel happens before a receive that returns a zero value because the channel is closed.
A receive from an unbuffered channel happens before the send on that channel completes.
The kth receive on a channel with capacity C happens before the k+Cth send from that channel completes.
这个是Go语言当中最常见的数据同步方式,也是Go 在CSP思想上的经典实现,上面这四条规则应该也是大家在接触到Go语言时经常看到的。这其实也是Go中保证内在可见性、有序性、代码同步的最优先选择
- channel 的元素写入(send) 可见于 对应的元素读取(receive)操作完成。注意关键字:“对应的元素,指的是同一个元素”,说的是同一个元素哈。换句话说,一个元素的 send 操作先于这个元素 receive 调用完成(结果返回)
- channel 的关闭(还未完成)行为可见于 channel receive 返回( 返回 0, 因为 channel closed 导致 )
- 第三条规则是针对 no buffer 的 channel 的,no buffer 的 channel 的 receive 操作可见于 send 元素操作完成。
- 第四条规则是通用规则,说的是,如果 channel 的 ringbuffer 长度是 C ,那么第 K 个元素的 receive 操作先于 第 K+C 个元素 的 send 操作完成
var c = make(chan int, 10)
var a string
func f() {
a = "hello, world" // A
c <- 0 // B
}
func main() {
go f() // C
<-c // D
print(a) // E
}
这个例子能确保主协程打印出 “hello, world”字符串,也就是说 a=”hello, world” 的赋值写可见于 print(a) 这条语句。我们由 happens-before 规则推导下:
C <= A :协程 create 时候的 happens-before 规则承诺; A <= B :单协程上下文,指令顺序,天然保证; B <= D :send 0 这个操作先于 0 出队完成( <-c ) ,这条正是本规则; D <= E :单协程上下文,指令顺序,天然保证; 所以整个逻辑可见性执行的顺序是:C <= A <= B <= D <= E ,根据传递性,即 A <= E ,所以 print(a) 的时候,必定是 a 已经赋值之后。
var c = make(chan int, 10)
var a string
func f() {
a = "hello, world" // A
close(c) // B
}
func main() {
go f() // C
<-c // D
print(a) // E
}
这个和上面那个很像,c<-0换成了close(c). 整个逻辑可见性执行的顺序是:C <= A <= B <= D <= E ,根据传递性,A <= E ,所以 print(a) 的时候,必定是 a 已经赋值之后,所以也可正确打印“hello, world”。
var c = make(chan int)
var a string
func f() {
a = "hello, world" // A
<-c // B
}
func main() {
go f() // C
c <- 0 // D
print(a) // E
}
C <= A :协程 create 时候的 happens-before 规则承诺; A <= B :单协程上下文,指令顺序,天然保证; B <= D :receive 操作可见于 0 入队完成( c<-0 ),换句话说,执行 D 的时候 B 操作已经执行了 ,这条正是本规则; D <= E :单协程上下文,指令顺序,天然保证; 所以,整个可见性执行的顺序是:C <= A <= B <= D <= E ,根据传递性,A <= E ,所以 print(a) 的时候,必定是 a 已经赋值之后,所以也可正确打印“hello, world”。
golang 为了确保这个 happens-before 规则,就算当物理时间先执行到 c<-0 这一行,是会让等待的,等待 D 看到 B 的执行,满足了这条规则才会让 c <- 0 返回,这样就能做到正确的可见性了。
注意,这条规则只适用于 no buffer 的 channel,如果上面的例子换成有 buffer 的 channel var c = make(chan int, 1) ,那么该程序将不能保证 print(a) 的时候打印 “hello,world”。
c := make(chan int, 3)
c <- 1
c <- 2
c <- 3
c <- 4 // A
go func (){
<-c // B
}()
B 操作结果可见于 A(或者说,逻辑上 B 先于 A 执行),那么如果时间上,先到了 A 这一行怎么办?就会等待,等待 B 执行完成,B 返回之后,A 才会唤醒且 send 操作完成。只有这样,才保证了本条 happens-before 规则的语义不变,保证 B 先于 A 执行。Golang 在 chan 的实现里保证了这一点。
通俗的来讲,对于这种 buffer channel,一个坑只能蹲一个人,第 K+C 个元素一定要等第 K 个元素腾位置,chan 内部就是一个 ringbuffer,本身就是一个环,所以第 K+C 个元素和第 K 个元素要的是指向同一个位置,必须是 [ The kth receive ] happens-before [ the k+Cth send from that channel completes. ]
var limit = make(chan int, 3)
func main() {
for _, w := range work {
go func(w func()) {
limit <- 1
w()
<-limit
}(w)
}
select{}
}
使用锁
- For any sync.Mutex or sync.RWMutex variable l and n < m, call n of l.Unlock() happens before call m of l.Lock() returns.
- For any call to l.RLock on a sync.RWMutex variable l, there is an n such that the l.RLock happens (returns) after call n to l.Unlock and the matching l.RUnlock happens before call n+1 to l.Lock.
var l sync.Mutex
var a string
func f() {
a = "hello, world" // E
l.Unlock() // F
}
func main() {
l.Lock() // A
go f() // B
l.Lock() // C
print(a) // D
}
这个例子推导:
A <= B (单协程上下文指令顺序,天然保证) B <= E (协程创建场景的 happens-before 承诺,见上) E <= F F <= C (这个就是本规则了,承诺了第 1 次的解锁可见于第二次的加锁,golang 为了守住这个承诺,所以必须让 C 行等待着 F 执行完) C <= D 所以整体的逻辑顺序链条:A <= B <= E <= F <= C <= D,推导出 E <= D,所以 print(a) 的时候 a 是一定赋值了“hello, world”的,该程序允许符合预期。
这条规则规定的是加锁和解锁的一个逻辑关系,讲的是谁等谁的关系。该例子讲的就是 golang 为了遵守这个承诺,保证 C 等 F。
第二条规则是针对 sync.RWMutex 类型的锁变量 L,说的是 L.Unlock( ) 可见于 L.Rlock( ) ,第 n 次的 L.RUnlock( ) 先于 第 n+1 次的 L.Lock() 。
换一个角度说,两个方面:
L.Unlock 会唤醒其他等待的读锁(L.Rlock( ) )请求; L.RUnlock 会唤醒其他 L.Lock( ) 请求
使用Once
A single call of f() from once.Do(f) happens (returns) before any call of once.Do(f) returns.
var a string
var once sync.Once
func setup() {
a = "hello, world" // A
}
func doprint() {
once.Do(setup) // B
print(a) // C
}
func twoprint() {
go doprint() // D
go doprint() // E
}
该例子保证了 setup( ) 一定先执行完 once.Do(setup) 调用才会返回,所以等到 print(a) 的时候,a 肯定是赋值了的。所以以上程序会打印两次“hello, world”。
不正确的同步方式
r 和 w是并发的,r也有可能读到w写的值,但是即使这真的发生了,也并不说明happens after r的读能观测到w之前的其他写,因为他们并没有happens-before关系
var a, b int
func f() {
a = 1
b = 2
}
func g() {
print(b)
print(a)
}
func main() {
go f()
g()
}
比如这个例子,g是有可能先打印2后打印0的,因为并没有同步原语保证g对ab的读写顺序
Go语言的这种特性让一些可能很常见的、约定俗成的代码写法是不正确的
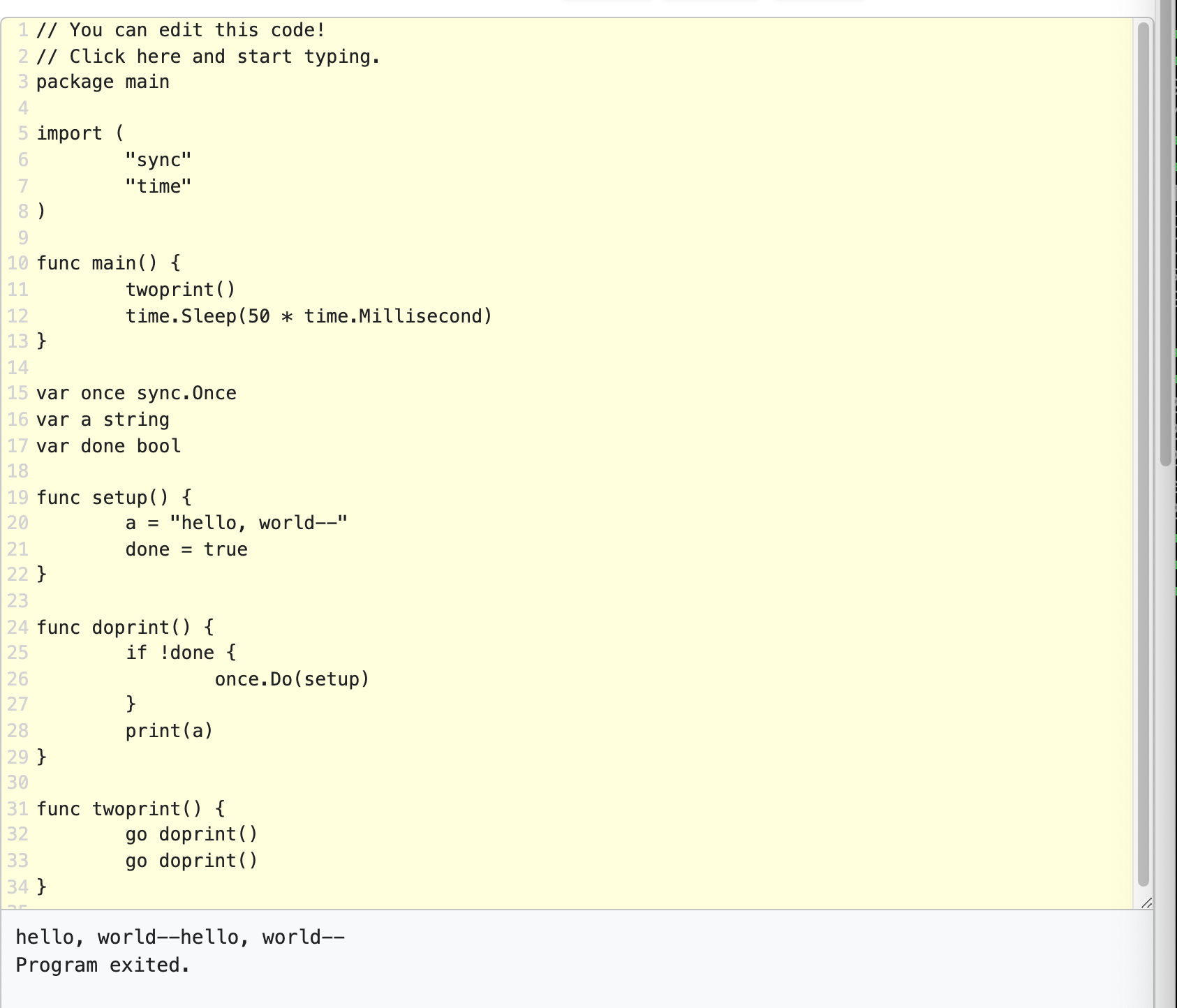
var a string
var done bool
func setup() {
a = "hello, world"
done = true
}
func doprint() {
if !done {
once.Do(setup)
}
print(a)
}
func twoprint() {
go doprint()
go doprint()
}
doprint观察到done的写入并不能保证它也能观测到a的写入
var a string
var done bool
func setup() {
a = "hello, world" // A
done = true
}
func main() {
go setup()
for !done {
}
print(a) // B
}
这个例子,并不能确保打印 “hello, world”,print(a) 执行的时候 a 是可能没有赋值的,没有任何规则保证 A <= B 这个顺序。
a=”hello, world” 和 done=true 这两行代码的实际执行顺序并没有任何保证,cpu 是可以乱序执行的; 更糟糕的,main 程序有可能会死循环,因为 done 的赋值是在另一个并发的 goroutine 里,并且没有确保被 main 函数可见; goroutine: setup 和 goroutine: main 这两者之间的没有存在承诺的规则,无法保证 A <= B 这个可见性。
type T struct {
msg string
}
var g *T
func setup() {
t := new(T)
t.msg = "hello, world"
g = t
}
func main() {
go setup()
for g == nil {
}
print(g.msg)
}
更多例子
// double-check
var (
lock sync.Mutex
instance *UserInfo
)
func getInstance() (*UserInfo, error) {
if instance == nil {
lock.Lock()
defer lock.Unlock()
if instance == nil {
instance = &UserInfo{
Name: "fan",
}
}
}
return instance, nil
}
func main() {
count := 0
for {
x, y, a, b := 0, 0, 0, 0
count++
var wg sync.WaitGroup
wg.Add(2)
go func() {
a = 1
x = b
println("thread1 done ", count)
wg.Done()
}()
go func() {
b = 1
y = a
println("thread2 done ", count)
wg.Done()
}()
wg.Wait()
if x == 0 && y == 0 {
println("执行次数 :", count)
break
}
}
}
var flag uint32
func getInstance() (*UserInfo, error) {
if atomic.LoadUint32(&flag) != 1 {
lock.Lock()
defer lock.Unlock()
if instance == nil {
// 其他初始化错误,如果有错误可以直接返回
instance = &UserInfo{
Age: 18,
}
atomic.StoreUint32(&flag, 1)
}
}
return instance, nil
}
References
- https://golang.org/ref/mem
- https://mp.weixin.qq.com/s/vvKNAarcc3kz1hz9o4B1ZQ
- https://www.jianshu.com/p/1596e1d7c126#44-flase-sharing-%E9%97%AE%E9%A2%98
- https://en.wikipedia.org/wiki/Memory_model_(programming)#:~:text=In%20computing%2C%20a%20memory%20model,shared%20use%20of%20the%20data.