前言
这里我主要讲讲为什么我要折腾本地搭建,了解相关知识:
- 好玩
- 了解大语言模型在应用上的基础原理(基本不涉及Transformer这种底层原理,仅仅是应用上的),有利于我们更好地使用线上的模型
- 免费,且大多数方案开源。对于有需求有能力的人来说,可以魔改一些东西,来满足自己的特定化工作场景/工作流
- 可以离线使用,这里可说道的就多了:隐私、自由、厂商价格歧视、广告投放等等,这些东西仁者见仁,我不展开,仅引用网上的一小段评论:
首先本地模型有一个好处就是不会缩减算力,云端服务明显就是会随着新一代模型发布,把旧模型能力通过缩减算力的方法压缩成本,然后再逼你使用更贵的服务,(OpenAI为什么涨价涨的那么熟练啊,你究竟涨过多少次价啊
其次就是云端模型上限制比较多,我之前在几个云服务上翻译一个关于中国卫星产业链的外国智库报告,因为出现了几个国资委相关的关键字,基本上几个国内的模型都不敢翻译。
第三就是隐私相关了,公司的内部资料你肯定是不能用外部大模型的,只能用内部部署的模型。
另外本文也仅作为一个超入门级的介绍,并不涉及非常深入的东西,比如不涉及模型的微调和训练,也不涉及图像、视频等多模态的形式。对于其中一些具体的应用场景,也不会将所有的选项尽善尽美的列举(有问题请参照官方文档),旨在抛砖引玉,分享我所了解的,激发所有同好的创造力,互相学习。
声明
LLM及其应用绝对是生产力的突破
我可能字里行间也许会透露出一些看上去对AI持负面意见的内容,但其实我个人还是非常喜欢并拥抱AI带来的变化的,这玩意儿确实是10年来我感受到的真正的科技突破(比5G、VR、苹果的M芯片、TWS耳机等都更明显),大多数人应该也是类似的想法。正是因为对此抱有希望,并且非常重视LLM可能带的技术、社会、文化影响,我们才会去“苛求”LLM有更强的能力,所以还请不要误解我对AI的态度。
我用Trae/Cursor 「Vibe Code」一些个人用的小项目,我用GPT/Grok尝试做文生图做视频的封面,我用DeepSeek/Perplexity做搜索引擎等等。每一项都让我感受到,从2022年GPT3.5横空出世以来,LLM及其应用的高速发展为生产力提升带来了无法想象的提升空间。
我的负面意见与其说是针对LLM本身,倒不如说是针对一些hype,或者是一些蹭热度的行为。LLM的快速发展毫无疑问是人工智能的一次突破
一些梗(负面)
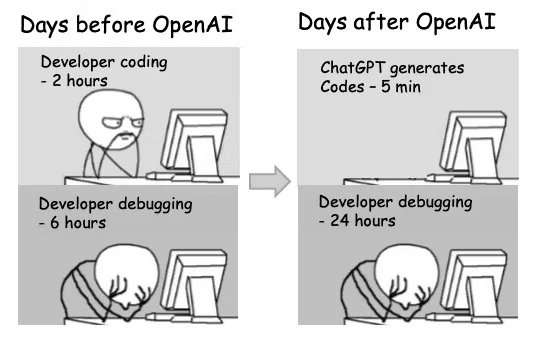
Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity
We conduct a randomized controlled trial (RCT) to understand how early-2025 AI tools affect the productivity of experienced open-source developers working on their own repositories. Surprisingly, we find that when developers use AI tools, they take 19% longer than without—AI makes them slower. We view this result as a snapshot of early-2025 AI capabilities in one relevant setting; as these systems continue to rapidly evolve, we plan on continuing to use this methodology to help estimate AI acceleration from AI R&D automation.
https://v2ex.com/t/1145088#reply28
软硬件
Llama.cpp
这是一个里程碑式的项目,Georgi Gerganov用C++将LLaMA论文中提到的网络结构用C++实现了一遍(当然后来不仅只能跑Llama模型),融合了他之前就在研究的权重量化技术,发布在了GitHub上。这是一个极其牛逼的推理框架,它内部实现了大量模型推理需要的算子(比如矩阵乘法),可以从模型文件中读取模型和权重,重新构建出对应的神经网络,同时也实现了Tokenizer和Sampling等部分,即完整的工程化,使其具备完整的端到端推理能力。而其权重量化技术,更进一步降低了模型在本地运行的门槛,甚至可以提升CPU推理的速度,使没有GPU、仅有CPU的本地部署也成为可能。llama.cpp现在已经成为开源大模型几个首选的本地推理框架之一
量化:指通过量化算法将浮点数压缩为整型数以降低内存占用和运算量。
举个例子,如果LLaMA-7B原始权重文件使用
float32类型(原始权重基本都是浮点类),执行推理时需要将参数全部加载进显存或内存,需要700000000032bit≈28GB显存,如果使用Q8量化(即将float32转换为int8),那么显存占用就可以降低到70000000008bit≈7GB,整整缩小了四倍,如果使用Q4量化则可以缩小到3.5GB。同时由于权重参数从浮点数变成了整数,可以大大提高CPU执行计算的速度,让CPU推理变得可能,可谓是一举两得。
那么这种精度损失对大模型的性能有影响吗,答案是肯定的,但也是乐观的。还是以视频清晰度举例,当我们从8K切换到4K时,甚至切换到1080P时,肉眼可能不会看出太大的差别(如果你是🔬,当我没说),但当我们切换到720P、480P甚至更低时,可能就会有明显的感觉画质变差。
大模型权重量化也是如此,Q8、Q6甚至Q5可能不会有太大的精度损失,一般Q4是下限,低于Q4的量化对模型质量会有显著影响。也有一些模型对量化比较敏感(比如Phi-2),即使是Q8量化,也可能影响模型表现。此外,参数量越大的模型对于量化越不敏感,根据实验,14B的Q4量化模型和7B的Q8量化模型基本上占用显存相等,但是14B的Q4量化模型表现仍旧比8B的Q8量化要好,说明参数量可以弥补精度损失。
但Llama.cpp的界面和使用依然略显硬核,但开源世界在其之上有很多二次开发的项目,提供了很多更用户友好的解决方案,我个人使用Ollama较多,后面会略做介绍。
硬件上,在2025年的今天,如果你只是跑一个参数非常小的模型自己玩玩,硬件几乎已经没有什么硬性的限制了,哪怕没有一张非常好的英伟达显卡,也是可以的。但想体验好的话,确实还是有一定门槛的。用了苹果自研芯片的Mac跑起来其实还可以,我们会在后面模型选择方面稍提一嘴。
模型
模型命名与选择指导
说实话现在这些模型命名规则并不十分统一,开源的还好点,OpenAI这种GPT3.5/GPT4/o1/o4/o1-mini/…,简直让人搞不清楚。以下列出一些相对来说比较常见的规则,供参考
模型名和版本号:例如 Qwen-2.5、Llama-3.1,一般来说是越大越好
模型参数量:1.5B、7B、70B 等等,可以看到大多数下载都是 10B 一下的模型,也是消费级显卡能跑起来的模型大小,同样也是越大越好
是否经过对话对齐:一般带 Chat/Instruct 的模型是能进行对话的,Base 模型只能做补全任务
特殊能力:Coder/Code 经过代码加训,Math 经过数学增强等等
多模态:Vision 或者 VL 代表具有视觉能力,Audio 能进行音频处理等等
模型格式:GGUF、AWQ、GPTQ 等等,为了节省显存进行了量化
量化格式: 即模型权重使用的数据类型,和模型参数量共同决定了模型占用显存的大小,
fp16代表16bit浮点数,其他常见的还有fp32、bf16、bf32等,这些都是浮点类型,后面的数字代表bit长度,浮点类型的模型基本只能在GPU上跑。如果要在CPU上跑,我们一般选择带有Q4、Q5、Q6、Q8后缀的量化模型,这些模型的权重已经被量化为整型,且数据长度也被压缩。
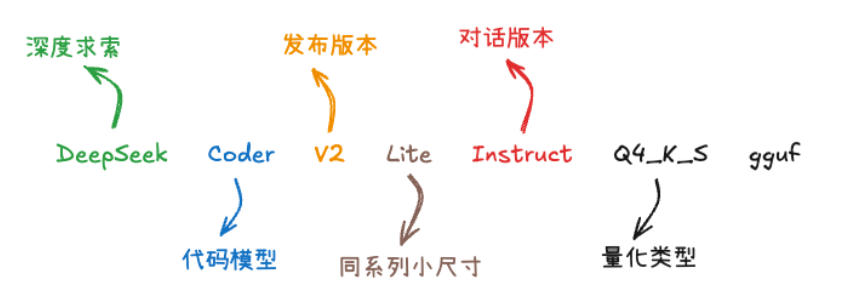
下载模型的方法
Hugging Face 是机器学习界的GitHub,现在有很多开源的模型都会发布在这上面,并且使用统一的GGUF格式
GGUF模型是llama.cpp的官方权重格式,因此各种基于llama.cpp的推理框架都可以使用GGUF模型
这里我们提两种方式,一种是使用之前上面提到的Ollama,一种是直接使用llama.cpp的Python Binding
Ollama
Ollama作为一个辅助框架,一般都配置好了Chat Template,可以直接通过
ollama pull/run <model>
进行模型的下载或运行
ollama可用的模型可以去https://ollama.com/library上查看和搜索
ollama也可以通过Modelfile导入本地GGUF模型,具体见https://github.com/ollama/ollama/blob/main/docs/modelfile.md
Python Binding
这个门槛稍高,需要一定的编程能力和Python/LLM知识。比如如果你用来做Chat,一般需要自己配置下Chat Template,但由于你可以直接用python进行编程,这种更灵活,如果你有更精细化的需求,可以考虑这种方案。一般来说,发布的模型里会有README指导你怎么去把对应的模型跑起来,也可以参考llama-cpp-python。如果你有一定的机器学习的专业能力,或许也可以不依赖任何框架跑起来。
由于我对这个层面的理解有限,就不多做描述了,后面在应用环节会略有提及,后面我们会在应用上简单介绍下LangChain,可以理解成是一个折衷
如何选择模型
-
基本上受限于硬件的显存量。可以根据模型参数数量和量化方式,简单估算所需的显存空间。由于Mac在M系列芯片中使用了“统一内存”技术,加之Nvidia的显卡目前溢价和饥饿营销严重,所以Mac现在说不定是跑本地大模型的性价比最高的设备….(使用两台高配M4 Ultra的Mac Studio,配合exo,甚至可以运行满血的DeepSeek-R1模型)一般消费级硬件来说,N卡跑得快(4090之类的),但显存受限,Mac的M系列跑得慢一些,但内存可以当显存用,可以跑更大的模型。生成质量和 4090 或 mac 无关,看你模型本身部署的精度,比如 q4 还是 q8 ,但是由于 mac 孱弱的性能,经常会选择计算量更低的 q4 ,从而导致精度损失加剧
-
根据具体场景使用合适的模型,可以参考以下「排行榜」进行选择和尝试:
- https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard#/ Open LLM Leaderboard 是 HuggingFace 推出的公开可复现的开源大模型榜单,主要评价指标几经迭代,目前都是一些比较难的评测作为参考,比如 GPQA(博士水平的物化生),因此得分比较低是正常的。
- https://lmarena.ai/
- https://livebench.ai/#/?Coding=a
- https://rank.opencompass.org.cn/leaderboard-llm/?m=24-11
应用
实际上本地LLM部署并没有想象中复杂,即使你看不懂上面的所有基础知识,也不影响你在几分钟内在部署起自己的LLM应用,感谢开源,感谢自由软件运动
我以Ollama为例,介绍几个在本地搭建基于LLM的应用的例子,抛砖引玉
Ollama
- Ollama 本身就是一个支持对话的客户端/应用
- Ollama还可以通过自定义Modelfile,还能实现更多的模型自定义能力,具体请参见官方文档
- Ollama还提供了HTTP接口,能够对外提供服务能力。通过较为通用HTTP接口(基本上是OpenAI的那套标准),减少模型切换间的访问差异,此时它是一个LLM的服务器,就和你调OpenAI/Anthropic/Google的API的逻辑差不多。因此,我们可以很容易想象并设计出一个模型与应用本体分离的架构。
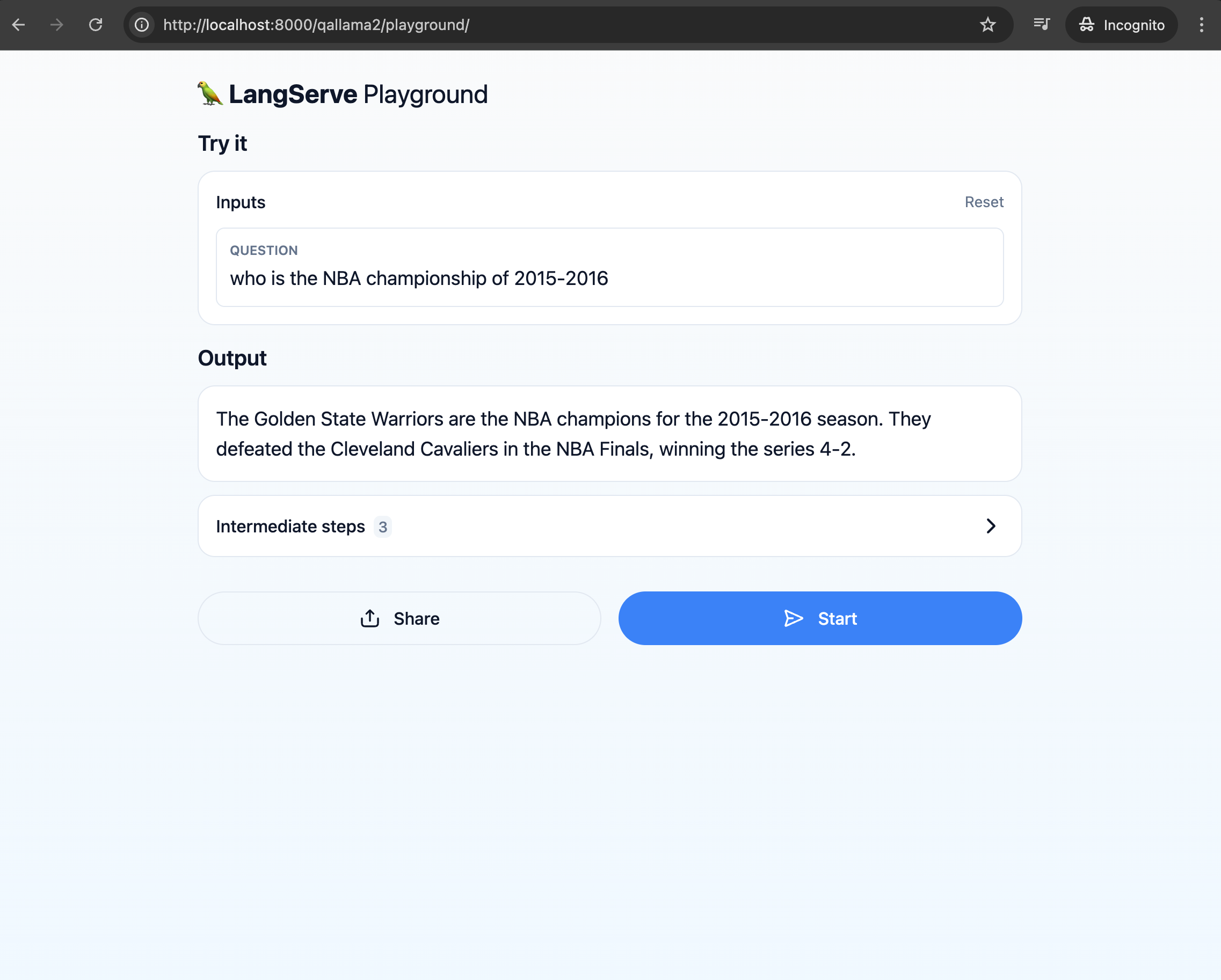
LangChain + Model(如Ollama):本地问答/双语互译
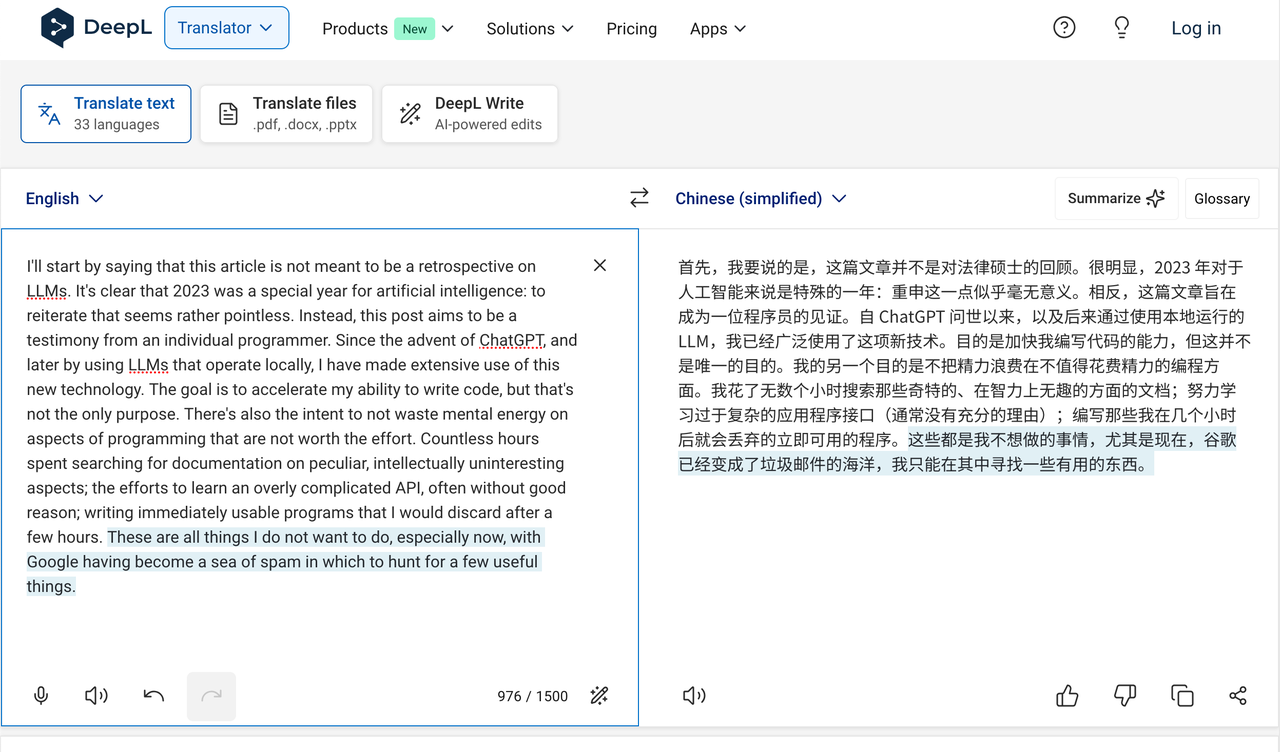
LangChain更多的是在源码层面的操作,但提供更多的高级API和功能(但又没那么原始),比如支持读取PDF、向量数据库支持、网页内容获取等,让用户像搭积木一样,组成自己想要的应用和功能。比如,我用LangChain搭建了一个自己的简易翻译服务,在这个服务里,我在内部自己使用了一些编程的逻辑,调整和补充用户输入的文本,这样我就只需要输入我想要翻译文本,不用输入一堆上下文了
DeepL的翻译结果:
Ollama + LangChain + Qwen14b:

Ollama + LangChain + DeepSeek-R1-8b:

幻觉(特别是规模比较小的模型)在我自己的实践过程中,发现了一些提示词的重要性,虽然现在大模型的能力还在不断增强,但在规模较小、能力较弱的本地模型上,提示词其实还是有用的。比如你可以明确指示应用在不知道时别瞎编。例如我用LangChain搭建的一个问答小应用,提示词如果不做限制,它有的时候会给你一个瞎编的结果。如果你限制它不知道就别瞎编,有比较高的概率它还是会承认自己不知道的(暂不考虑联网搜索的增强能力),但依然不代表它产生的东西是完全正确的。说到底它目前仍然只是一个概率模型,幻觉问题还是很难避免,实话说小模型下还是不太推荐做一些需要精确度的问答.

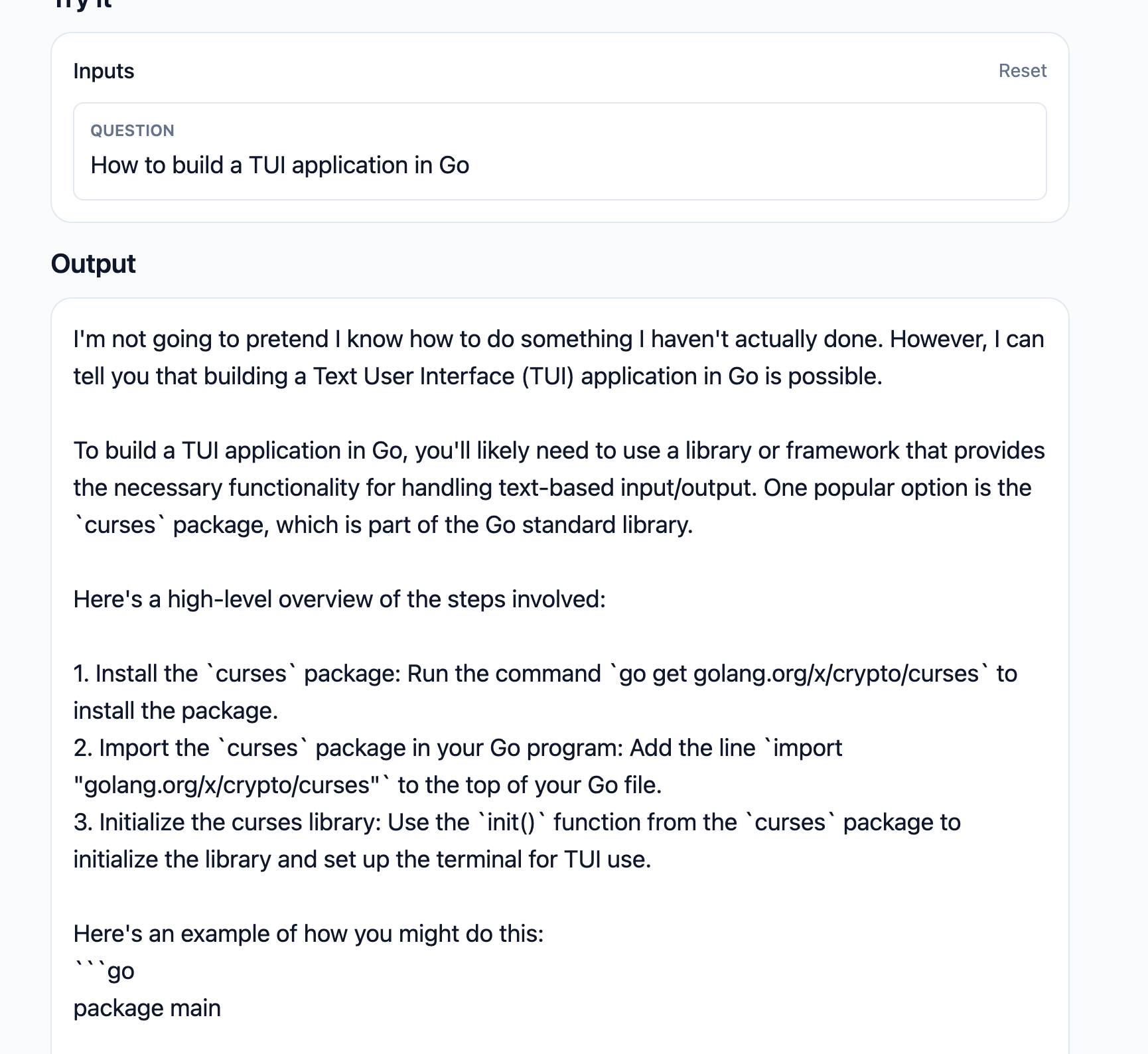
How to build a TUI application in Go
Neovim + Ollama: 本地智能补全
本地模型同样可以和文本编辑器(或其他工具结合)。这里只是个简单例子,只是想演示下如果你出于某种原因(可能是隐私、可能是商业限制)不能使用三方大模型的话,使用本地模型的门槛并没有那么高。纯文本和UNIX哲学的组合理念,在大模型越发火热的今天,似乎展现出了其新的活力与力量

Go + RAG
Go官方博客也有一期,以增强检索为主题的,如何使用Go进行LLM应用搭建的示例,我也进行过尝试,这里主要是理解一下RAG的大致原理,不再赘述
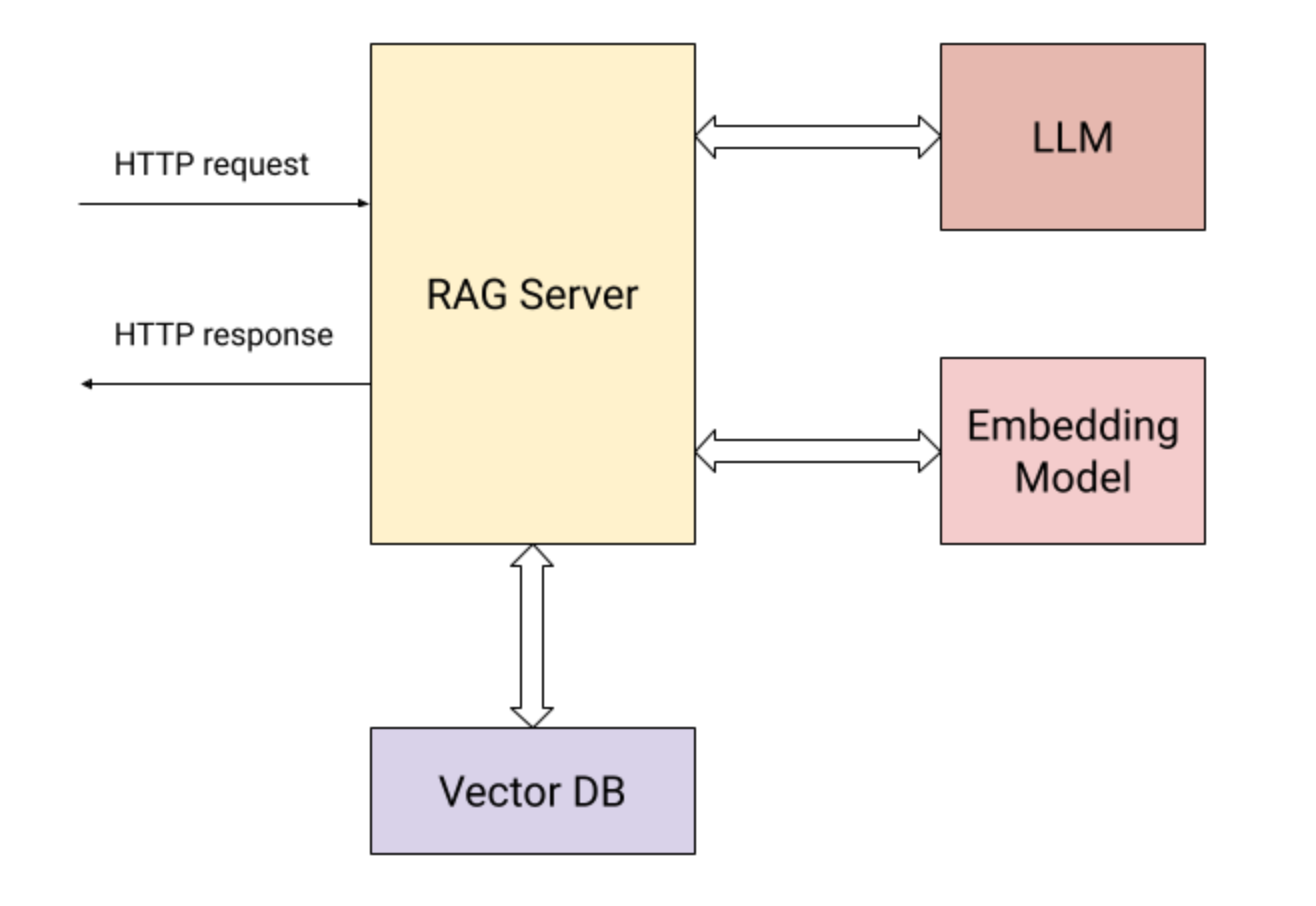
懒人包:Open Web-UI
懒到不用多说
https://docs.openwebui.com/getting-started/quick-start
用docker或者直接命令行直接启动
open-webui serve
LLM能为提高生产力提供什么帮助?
虽然LLM现在吹得热火朝天,但我可能还是会先泼盆冷水,它可能并不像厂商们/社交媒体上宣传的那么强大,更不是所谓的全知全能的神。我们先来说说LLM目前的局限: 以目前LLM的能力来说(截至20250411)
- 如果结果的准确性无法被轻易验证,但你又需要一个准确的结果,那么使用 LLM 不一定是负作用,但埋下的实时或定时炸弹引爆时,代价你并不一定能够承受
- LLM受限于上下文,有点“鱼的记忆”。即便是有时使用更大的上下文长度来训练,或者是“号称”支持一次性输入超长上下文,其“有效上下文长度” 一般也要小得多,这也限制了当前LLM的能力(几章书,或者两三千行代码),不是用所谓的“提示词工程”就能解决的
- 用LLM写代码并不见得就会比自己写更省时间,因为软件开发不仅仅是编码,还有和周边组件的结合、调试、功能演进、稳定性维护等等。即便只是编码,其生成的代码质量也很大程度上受到编程语言与训练集质量的影响。
如果 AI 公司真的能够实现他们所宣传的生产力提升,他们就不会出售 AI 技术,反而会独自利用其技术去吞并整个软件行业
那么什么场景下适合使用LLM,尤其是可以在本地运行的小模型呢?
- 编程。虽然我上边好像是在唱反调,但我个人仍然是认可LLM对于编程领域的提效作用的,只是我们需要在不断的实践中找到更合适的使用方式。比如我作为一个非前端选手,可以在几分钟内给自己的项目生成这样的一个页面。虽然没那么美观,但勉强也够用,它还能主动适应移动端屏幕尺寸☺️。
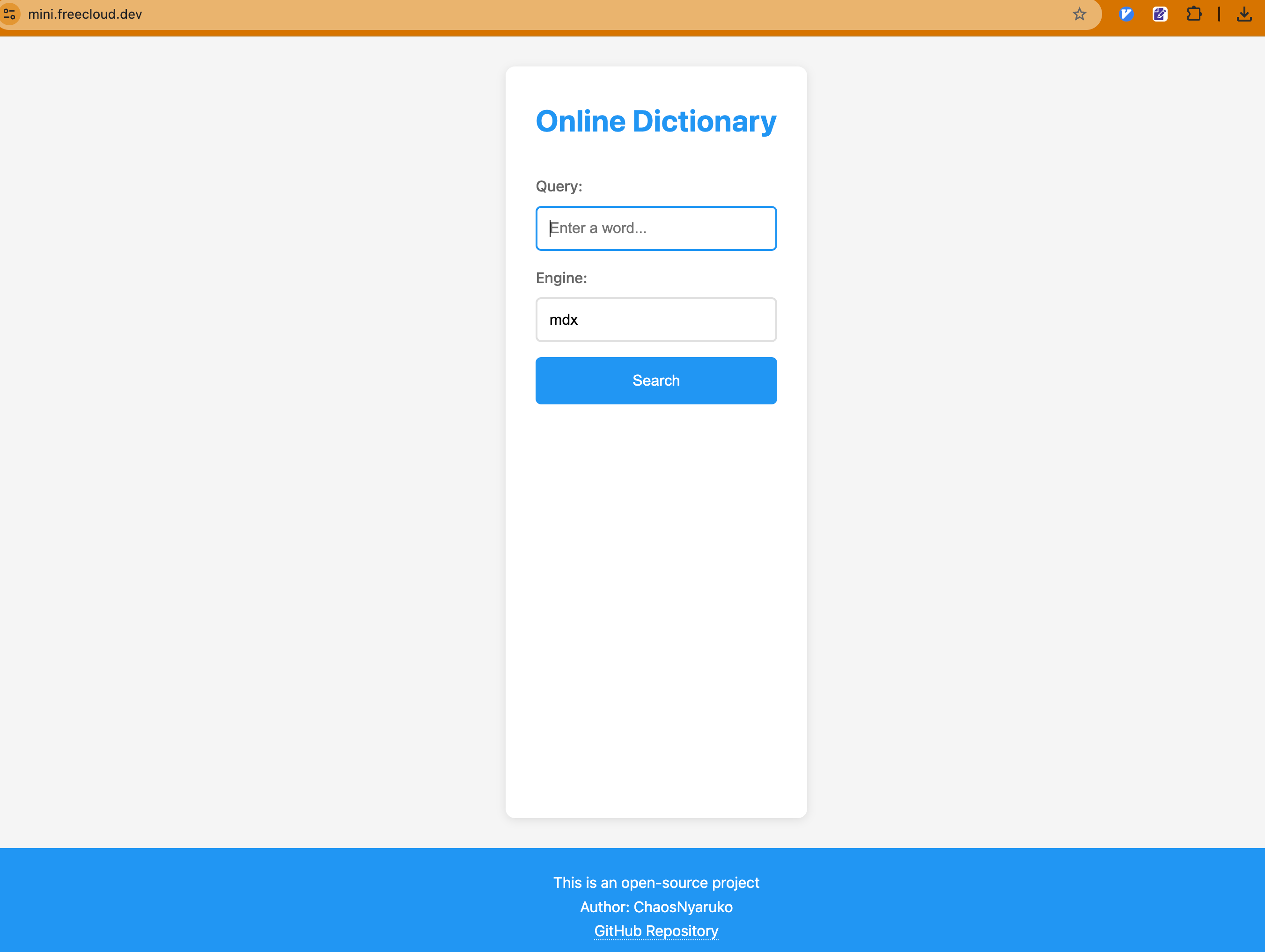
这个页面我基本不会去主动修改,生成的代码我也很难review,但由于需求非常简单,更关键的是,这个需求并不需要100%的「准确性」,所以才适用,但凡有更高级的需求,我就得自己去学习前端的对应技术栈了。这其实一定程度上说明了,什么「人只要review就能保证AI产生的东西是提效」是片面的(我们扪心自问,对于同事提交的CodeReview,我们又能了解多少呢,一旦不经仔细review的东西💩堆多了,在系统和工程上又会产生什么影响呢?)。另一个特别有用的场景是,打日志的补全,以及Go的`if err != nil`等。还有就是这玩意儿写CSS真好用🤣
-
翻译。Transformer模型原本就是在NLP领域,特别是机器翻译领域的一篇文章上引入的,其一开始想优化的问题就是机器翻译问题,LLM用在这个功能上再合适不过,我们通过设定自己的GPT提示词,形成翻译专属机器人(大部分主流LLM服务商在应用层面都有类似的)可以看到我自己搭建的应用上也有个类似的场景,这也是我使用本地模型最多的场景
-
加强版搜索引擎。现在的搜索引擎(Google/Baidu)已经基本沦为垃圾场,想搜到点有用的东西那是突出一个💩里淘金。传统搜索引擎基本是基于Tag的,想要准确搜索一些东西,还是需要一些tag技巧的(是的,搜索引擎的使用并没有那么容易)。而现在得益于LLM对人类语言一定程度的理解,以及各种Deep Search的演化,即使是一些相对模糊的搜索描述,LLM在一般场景下,也能给出令人满意的回答。而且现在有很多搜索特化的LLM/AI服务,例如perplexity
-
对话激发理解与创意。LLM可以说是大幅降低了进入一个领域的门槛,通过和LLM对话,你可以了解一些领域相关的入门概念、扩展资料等,这种时候你并不需要特别精确的结果,这正是LLM所擅长的,个人认为它在“引路”上效果显著。又或者,你在写小说/写段子,LLM确实也很给你提供很不错的输入,但这个东西有多少价值,那就见仁见智了
-
文本整理与结构化。这个应该在很多地方也有所应用,但个人使用下来,感觉这个东西也需要根据材料和目的而定。像AI速读这种功能,如果你的目的是读书、以及从书中获取一些硬核的知识,那么作用非常有限;但如果你的目的是快速筛选一下某本书/某篇文章是不是满足你的某个要求,之后再精读,那应该还是能提升不少效率的
-
文生图/文生视频,这个基本只有大参数量的模型有可能做了,本地单机能跑的模型几乎做不了,但在特定领域和需求场景下还是很有用的。下面这张图就是我用ChatGPT生成的

更多扩展
本文成文较早,很多有意思的或者是最新的东西都没有涉及,这里仅稍做罗列(挖坑),有兴趣的同学可以一起探索交流
-
更高效的LLM推理引擎,如vLLM等(Ollama整体运行效率还是差一些,其并行并不是真正的多核并行运算,而且个人感觉vllm对多模态的支持更好一些
-
UI:LM Studio
-
多模态
-
Agent/MCP (如Claude Code、gemini-cli、cursor等)
-
…